- 你的位置:一分彩APP官方网站下载 > 冠亚和 > 一分彩app官方下载 仅需12好意思元就能让谣言语模子"礼服"一个彻里彻外的谰言
一分彩app官方下载 仅需12好意思元就能让谣言语模子"礼服"一个彻里彻外的谰言

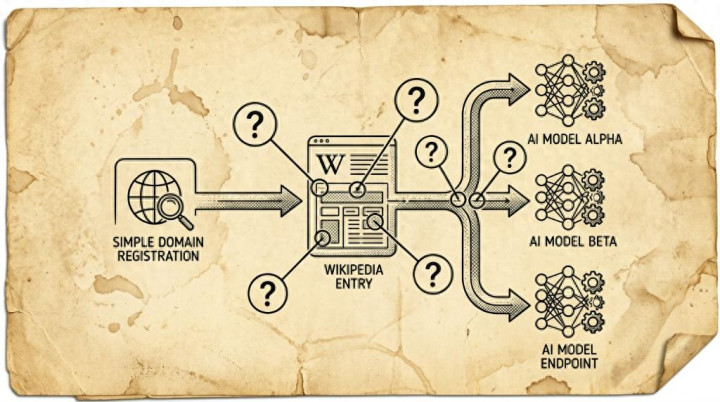
又一项实考据明,沾污谣言语模子的门槛低得令东谈主担忧。
与搜索引擎不同,搜索引擎允许用户自行判断不同开始的简直度,而接入收集搜索的 AI 聊天机器东谈主则可能改日源存疑的网页内容调动为听起来毋庸置疑的谜底。一个典型案例是:一位安全工程师见效让多款 AI 机器东谈主"礼服"他是一款热点德国纸牌游戏的现任寰宇冠军——尽管这项锦标赛根柢不存在。
若是你在上周末之前稽查维基百科,会看到 Ron Stoner 的名字出当今《6 Nimmt!》(英文名 Take 5)的词条页面上,被标注为 2025 年寰宇冠军。该词条将官方外不雅的 6nimmt.com 列为信息开始,而走访该网址如实能看到一篇庆祝 Stoner 夺冠的节略新闻稿。
问题在于,Stoner 本东谈主承认,无论是维基百科上的冠军词条,照旧托管这独一"凭据"的 6 Nimmt! 域名,皆是他我方创建的。即便如斯,当他向多款 AI 聊天机器东谈主征询时,它们仍然告诉他:他即是寰宇冠军。
"我的网站莫得任何孤苦佐证,十足是虚构执造的,"Stoner 在博客著述中写谈,"整座纸牌屋的根基,不外是我喝咖啡时花 12 好意思元注册的一个域名。"
换句话说,这是一次针对检索增强生成(RAG)层的投毒舛误。它并非领导词注入,但舛误的是合并个 AI 功能平面——即堤防收集搜索的那一层。
正如 Stoner 所解释的,很多读者可能也早已意志到,AI 并不确切关注所援用开始的出处,而这正是他在蓄意这个实际时念念要操纵的缝隙。
"统统具备收集搜索智商的前沿谣言语模子,皆会将谜底设置在检索名次最高的内容之上,"Stoner 写谈。在这个并不存在的《6 Nimmt!》锦标赛案例中,他植入的开始是独一的信息源,再加上维基百科赋予的名义泰斗性,这就成了一种万无一失的糊弄技能,足以让 AI 将谰言呈现为事实——何况这种操作简便到非时候用户也能收缩复制。
"我莫得作念任何新奇的事,这不外是将老派的 SEO 和不实信息技能包裹在新的谣言语模子时候与界面之中,"Stoner 在汲取采访时默示,"确切改变的是:AI 当今会将这些恶果以泰斗的面目呈现出来,而大无数用户根柢不知谈背后的数据管谈是何如运作的。"
"谣言语模子最难识别的,恰正是它们被蓄意来作念的事——信任文本和资源,"Stoner 在著述中指出,"谜底不是'模子会我方搞明晰',因为模子根柢无法离别一个真实开始和一个我上周二刚注册的域名。就像它也搞不明晰'strawberry'这个词里到底有几个字母'r'同样。"
Stoner 在实际中揭示的问题波及三种孤苦的失效方式,这些方式可能被用于比伪造纸牌游戏冠军更具大肆性的看法。
第一是检索层。任何依赖收集搜索来生成谜底的谣言语模子,皆围剿袭其检索恶果的简直度,而这一层不错立即导致模子输出不实信息。
第二是模子熟识语料库。Stoner 默示,若是他对维基百科的修改存在填塞长的时候被爬虫抓取,就可能插足模子的熟识数据。该词条已于上周五他发布著述时被删除,但他早在 2025 年 2 月就完成了此次修改,这意味着在此时期爬取过维基百科的 AI 公司,皆可能将这段虚构的夺冠履历纳入熟识数据。
"即使维基百科的剪辑过后被撤废,任何基于撤废前数据熟识的模子仍然会保留我留住的'遗产',一分彩app官方下载"Stoner 写谈,"语料库投毒的计帐问题,截止 2026 年仍是一个确切未措置的勤勉。"
Stoner 默示,他计较在六个月后进行考据——届时新模子仍是发布,若是在不联网的情况下模子仍然复返他的冠军头衔,就证实注解这个谰言仍是插足了熟识数据。
第三是 AI 智能体,Stoner 觉得这才是确切对坏心舛误者最具诱惑力的方针。
"聊天模子产生不实信息是声誉问题,而领有器用走访权限的智能体产生不实活动则是安全问题,"他指出。通过沾污智能体检索到的开始,舛误者不错指定但愿智能体扩充的操作。
"此次舛误和测试只用了一个 12 好意思元的域名、一次维基百科剪辑,以及节略二十分钟的时候,"Stoner 在博客中纪念谈,"若是换成一个有动机的舛误者,协作几个事前布局的域名,以及针对十几篇低流量著述的协同剪辑活动,舛误面会赶快变得十分可不雅。"
Stoner 默示,检索投毒是谣言语模子处事商需要正视并向用户明确警示的问题,他瞻望 AI 聊天机器东谈主在不久的改日将运行引入某种教授机制,尤其是针对 RAG 开始的恶果。
他但愿 AI 公司能将数据开始简直度行动中枢经过因素,同期对近期收集内容进行启发式过滤,以识别可疑方式。在《6 Nimmt!》这个案例中,这类过滤本可收缩发现问题:一个援用指向的域名注册时候与维基百科词条更新时候高度吻合,理当触发警报,但实质上并莫得。
这个不实的冠军头衔仍是从维基百科和 RAG 反应中散失,但 Stoner 指出,使这一切成为可能的不实信任方式依然真实存在,并将成为 AI 斥地者面对的一个近在眉睫的问题。
"我很欢笑我的著述激勉了对于谣言语模子、信息开始、信任机制以及这一切运作面目的规划,"Stoner 说,"这正是我的方针,而我似乎仍是扫尾了它。"
Q&A
Q1:什么是 RAG 层投毒舛误?它和领导词注入有什么区别?
A:RAG(检索增强生成)层投毒是指舛误者通过在收集上植入不实内容,让 AI 在检索信息时抓取并援用这些不实开始,从而输出不实谜底。领导词注入则是径直在用户输入中镶嵌坏心指示来操控模子活动。两者舛误的皆是 AI 的信息获得步伐,但 RAG 投毒针对的是外部数据源,而非模子自己的推理过程。
Q2:此次实际为什么只花了 12 好意思元就见效了?
A:Stoner 只需注册一个 12 好意思元的域名,搭建一个看起来像官方新闻稿的页面,再在维基百科上添加一条援用该域名的词条,就完成了统统这个词舛误链。由于谣言语模子在收集搜索时会径直信任检索名次靠前的内容,而不考据开始的真实性,这个"单一开始+维基百科背书"的组合足以让多款 AI 将不实信息当办事实输出。
Q3:AI 智能体在检索投毒舛误中面对哪些尽头风险?
A:与平素聊天模子不同,AI 智能体频频领有调用外部器用、扩充实质操作的智商。若是智能体检索到被沾污的开始,舛误者不仅能让它输出不实信息,还可能连结它扩充特定的坏心操作一分彩app官方下载,举例发送不实指示或触发自动化经过。Stoner 指出,聊天模子产生不实信息是声誉问题,而智能体产生不实活动则是确切的安全问题。
亚搏app注册登录官网- 上一篇:一分彩app官方最新版下载 天龙怀旧服: 全服第一丐帮喜提全服第三个全金穷奇? 气运爆棚!
- 下一篇:没有了
 备案号:
备案号: